
La canonicalizzazione delle URL è l’attività attraverso cui un motore di ricerca stabilisce il contenuto di riferimento quando trova occorrenze in più di una URL. É un argomento molto importante nell’ambito dell’ottimizzazione per i motori di ricerca, tanto da influenzare pesantemente la possibilità delle tue pagine di comparire nei risultati.
Molto spesso, la questione legata alla canonicalizzazione delle pagine viene semplificata e ridotta alla conoscenza e implementazione del rel Canonical. Questo tag è una soluzione più che valida per la corretta segnalazione dell’URL canonico, forse anche la migliore, ma non è l’unica strada che puoi percorrere per segnalare correttamente al motore di ricerca quali sono i tuoi contenuti canonici.
In questo articolo cercherò di fornirti alcune basi di conoscenza per gestire correttamente la canonicalizzazione delle URL. Analizzerò con te cos’è e perché è così importante per il ranking sui motori di ricerca, come puoi implementarla all’interno del tuo sito (con alcuni esempi basati su WordPress, ma azionabili praticamente su qualsiasi CMS esistente) e in quali casi dovresti prestare particolare attenzione.
Alla fine, grazie alle istruzioni diffuse dalle linee guida dei motori di ricerca, vedremo insieme anche una essenziale carrellata degli errori più comuni commessi dai webmaster nella definizione dei contenuti canonici.
Indice dei contenuti
Cos’è la canonicalizzazione delle URL
Come anticipato nell’apertura del post, la canonicalizzazione delle URL è il processo attraverso cui il motore di ricerca identifica contenuti troppo simili comuni a differenti pagine di un sito web e stabilisce, una volta effettuati tutti i controlli, quale sia quello da ritenersi come principale (o canonico).
Il processo di determinazione delle URL canoniche è molto importante per i motori di ricerca. Lo stesso Google ne parla in uno dei suoi contenuti per i developer in riferimento all’operazione di deduplicazione, svolta dai crawler per determinare quale sia, fra le pagine che condividono contenuti, quella da ritenere “giusta” per essere mostrata nella sua ricerca.
“La canonicalizzazione è il processo di selezione dell’URL canonico rappresentativo di un contenuto. Di conseguenza, un URL canonico è l’URL di una pagina che Google ha scelto come più rappresentativo tra un insieme di pagine duplicate. Questa procedura, spesso chiamata deduplicazione, consente a Google di mostrare nei risultati di ricerca solo una versione dei contenuti, che altrimenti sarebbero duplicati.“
Fonte: Google Search Central, “Che cos’è la canonicalizzazione“
Il concetto di canonicalizzazione sottintende un altro caposaldo della disciplina SEO: quello dei contenuti duplicati.
I contenuti duplicati
Non approfondirò qui l’argomento, ma è importante che tu sappia che i motori di ricerca generalmente non hanno una grandissima considerazione dei contenuti duplicati, ovvero quei contenuti che si ripetono in più pagine di un sito web in percentuale più o meno sostanziosa.
La duplicazione rende la vita ai crawler molto difficile. Vista la ridondanza di URL che trattano il medesimo argomento, i bot potrebbero fare fatica a determinare quale dei contenuti meriti il diritto di essere mostrato agli utenti nelle pagine dei risultati del motore di ricerca.
Per capirli un po’ meglio, ti faccio l’esempio del bibliotecario.
Immagina di essere un bibliotecario. Hai due libri identici, con lo stesso contenuto, lo stesso titolo e lo stesso autore. Quello che cambia è soltanto la copertina, oppure la sinossi della storia.
Come li catalogheresti?
Probabilmente sceglieresti di mettere in catalogo solo uno dei due libri, destinando l’altro al magazzino. Che senso ha disporre due copie dello stesso libro nella tua biblioteca? Certo, la tua struttura è grande, le sale enormi e le librerie arrivano fino al soffitto.
Ma i libri da archiviare sono sempre di più e, prima o poi, lo spazio inizierà a scarseggiare.
I crawler di Google e degli altri motori di ricerca si comportano un po’ allo stesso modo e hanno problemi molto simili. Se due contenuti di un sito web sono tanto simili, ha senso che consumi risorse per tenerli entrambi? E se sono così simili da risultare necessario averli entrambi in indice, quale deve essere indicizzato e mostrato agli utenti nella SERP?
Qui entra in gioco la canonicalizzazione.
E attenzione: parlo di contenuto non faccio riferimento soltanto al testo. Immagini, video e, più in generale, contenuti realizzati in altri tipi di media possono essere soggetti a duplicazione.
Cosa può generare le duplicazioni da canonicalizzare?
Ti immagino già pensare ai contenuti che hai pubblicato recentemente. Saranno univoci? Avranno ognuno una sua indipendenza, risponderanno ciascuno a un’intenzione di ricerca determinata e inequivocabile?
Ovviamente non so dirtelo. Quello che posso dirti, invece, è che la maggior parte dei contenuti potenzialmente duplicati li hai in casa e magari non te ne sei nemmeno mai accorto.
Quando si parla di contenuti duplicati si immaginano subito articoli blog, pagine di vendita, schede prodotto e via dicendo. Di base si pensa al contenuto scritto nelle pagine. Ci sta, la duplicazione può assolutamente succedere in tutti quei casi.
Ti faccio però una domanda: come stai gestendo i risultati del tuo motore di ricerca interno? E i filtri? Le varianti regionali, se hai un sito multilingua?
Ecco: questi sono i nemici più pericolosi. Quelli silenziosi, che si nascondono così bene in bella vista che rintracciarli diventa difficilissimo.
La maggior parte dei problemi di duplicazione si verifica involontariamente. Alcuni posti in cui potresti andare a cercare contenuti duplicati:
- sono disponibili sia la variante in http che quella in https del tuo sito;
- sono disponibili sia la variante www che quella non-www del tuo sito;
- hai dei filtri di ricerca nelle tue pagine di listing;
- hai delle opzioni di visualizzazione nelle tue pagine di listing;
- hai un motore di ricerca interno;
- hai ancora online lo staging del tuo sito;
- hai attiva una versione mobile e/o AMP.
Queste casistiche generano, da sole, la maggior parte delle duplicazioni involontarie sul tuo sito web. E non dipendono tanto da qualcosa che hai fatto, quanto piuttosto da qualcosa che non hai gestito.
Esempio di duplicazione per cui è necessario canonicalizzare
Pensa alle pagine dinamiche, quelle cioè che si generano dopo la selezione di un valore specifico in una pagina come la categoria di un e-commerce. Le riconosci perché, generalmente, sono URL parametrate, ovvero riportano nello slug il parametro che le ha attivate.

Quella che vedi sopra è una delle pagine di categoria di Ikea. La parte cerchiata in rosso, l’URL della pagina, mostra chiaramente che ci troviamo in una categoria di prodotti, nello specifico quella delle scrivanie da gaming (si… è una ricerca interessata!).
Ora, cosa succede se chiedo al sito di mostrarmi le scrivanie di colore rosso?
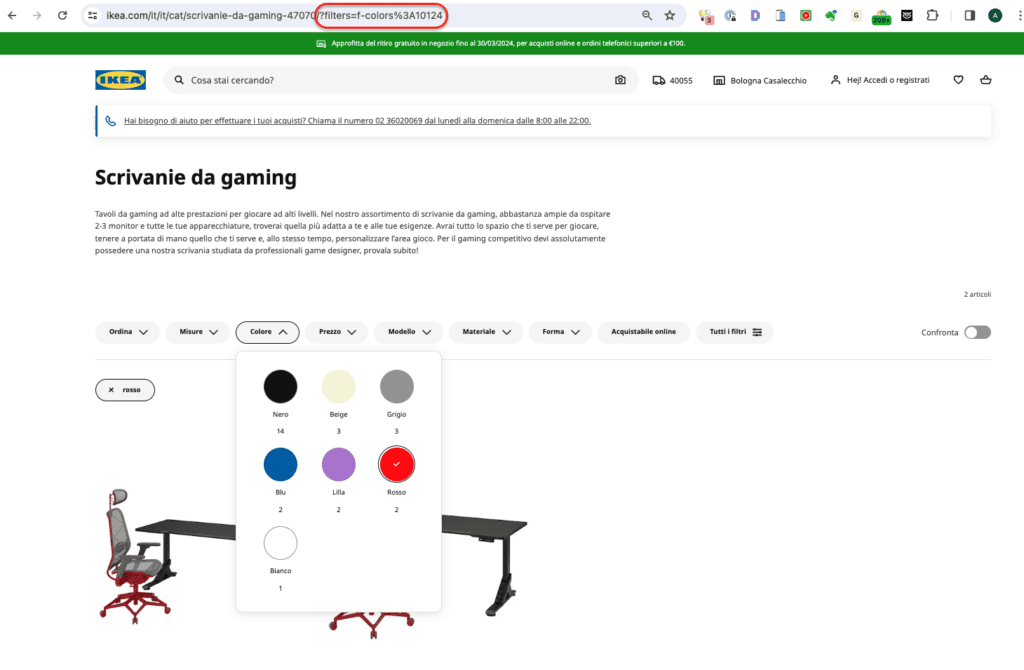
A parte l’ovvia ridistribuzione degli articoli in frontend, guarda com’è cambiata l’URL cerchiata in rosso. All’indirizzo originale si è aggiunto un parametro: ?filters=f-colors%3A10124. Quello è un parametro, grosso modo l’indicazione di mostrare solo alcuni elementi della pagina.
Oltre ai prodotti visualizzati e all’URL, cos’è cambiato? Prenditi qualche istante e dai uno sguardo alle due immagini sopra. Oppure cerca la pagina direttamente in SERP (magari aggiungi anche “ikea” dopo “scrivanie gaming”, così da trovare subito la pagina che cerchi).
Bene, fatto? La risposta è: nulla.
Title identifico, testo identico. La maggior parte del contenuto è identico. Le due URL https://www.ikea.com/it/it/cat/scrivanie-da-gaming-47070/ e https://www.ikea.com/it/it/cat/scrivanie-da-gaming-47070/?filters=f-colors%3A10124 contengono contenuti duplicati.
Questo problema si verifica di fatto per qualsiasi URL generata da parametri che non sia esclusa dall’indice (ad esempio con un istruzione Disallow da file Robots.txt, da creare prima della messa online dei contenuti).
Anche i motori di ricerca interni dei siti possono creare lo stesso problema, specialmente se pensi a due pagine di un e-commerce che non hanno testo.
Guarda le due immagini che seguono.
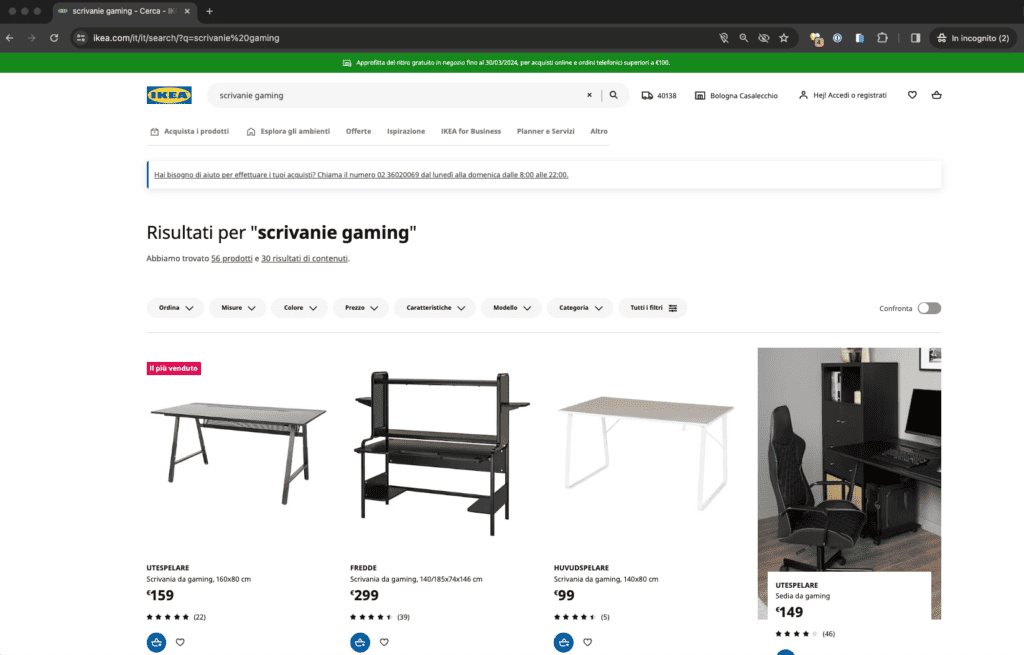
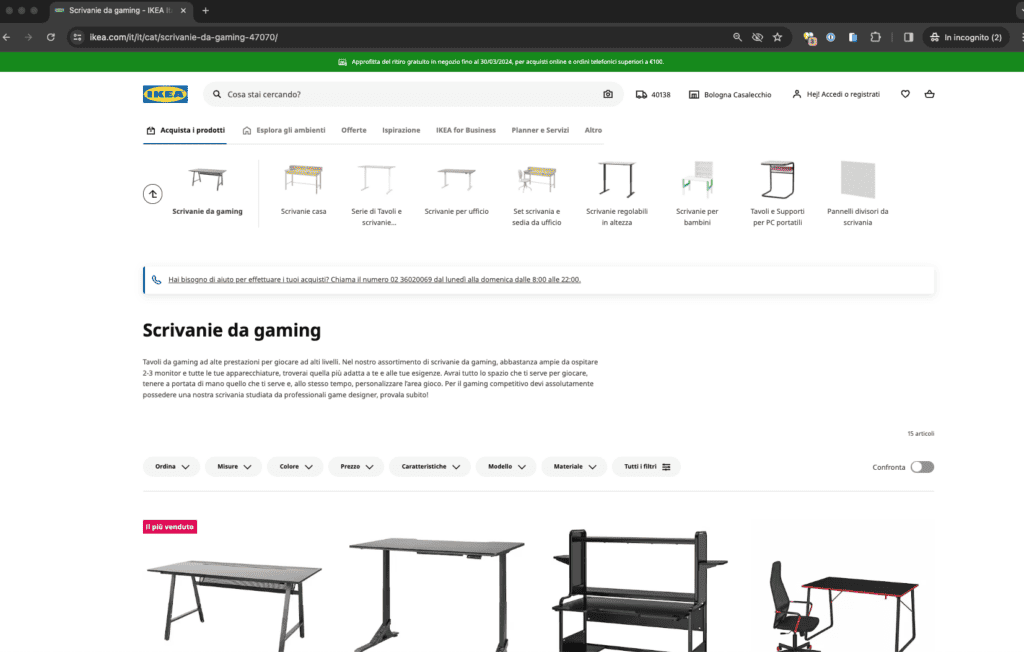
Sembrano molto sili, vero? A parte un paio di prodotti differenti e il testo (che in una è presente e nell’altra no), tutto sommato si somigliano molto. Anche il tag Title è molto simile: “Sembrano molto sili, vero? A parte un paio di prodotti differenti e il testo (che in una è presente e nell’altra no), tutto sommato si somigliano molto. Anche il tag Title è molto simile: “scrivanie gaming” nella prima, “Scrivanie da Gaming” nell’altra.
Bene, sappi che la prima è la pagina di risposta del motore di ricerca interno di Ikea, che compare se cerchi “scrivanie gaming”. La seconda è la stessa pagina di categoria vista in precedenza.
Anche in questo caso, se non tratti il rapporto fra queste due pagine (e fra tutte le pagine che hanno un rapporto simile), rischi di trovarti con contenuti duplicati non gestiti e conseguente possibilità di perdere terreno in SERP.
Ikea lo gestisce secondo me piuttosto bene. Se vuoi scoprirlo da te, ragionaci su! Io approfondirò la questione di come si gestisce la canonicalizzazione un pochino più avanti.
Altri esempi sono più difficili da supportare con immagini, ma te li riassumo a seguire:
- controlla che la versione non-www del tuo sito sia reindirizzata verso la versione www (o viceversa, a seconda della versione che hai scelto come principale). Se www.dominio.it (versione non principale) non reindirizza su dominio.it beh… il tuo intero sito è duplicato;
- discorso simile per la versione http vs https. Fermo restando che la versione http ormai sarebbe meglio non ci fosse proprio più, assicurati che le sue URL siano correttamente reindirizzate verso la loro versione https. Altrimenti, stesso problema del punto precedente.
- se utilizzi ancora AMP per il mobile o semplicemente hai un sito m.dominio.it, sappi che le URL www.dominio.it/single-post/ e www.dominio.it/amp/single-post/ fanno riferimento a due pagine differenti. Stesso discorso per le pagina www.domino.it/single-post/ e pagina m.dominio.it/single-post. Considerando che il contenuto sarà praticamente lo stesso, anche in questo caso la duplicazione va gestita.
Ricapitolando: ogni qual volta ti trovi, volente o nolente, ad avere contenuti simili all’interno di due o più pagine devi fare qualcosa.
Perché la canonicalizzazione è importante?
Ci sono ovviamente svariati motivi per cui è importante canonicalizzare correttamente le URL del tuo sito. Alcune sono squisitamente legate all’ottimizzazione SEO, altre sono utili per facilitare il lavoro soprattutto in fase di analisi.
Accorpamento dei segnali di ranking
Immagina la situazione che ti ho mostrato sopra. Ho pagine che, in un modo o nell’altro, possono essere considerate duplicate. Per rimanere in tema “scrivanie gaming”, nello specifico, questa situazione si manifesta:
- per tutte le pagine costruite dalla selezione dei filtri;
- per tutte le pagine costruite nel motore di ricerca interno.
Il mio Brand non è particolarmente famoso (non sono Ikea, per capirci), quindi ogni citazione (a.k.a. backlink) io possa ricevere dall’esterno è importantissima.
Cosa succede se la pagina a ricevere link non è soltanto la categoria “scrivanie gaming” ma anche, ad esempio, l’URL parametrata con un filtro di prezzo o quella con l’ordinamento di prezzo ascendente?
Semplice: stai “sprecando” Page Rank. O quanto meno non lo stai usando proprio benissimo. Stessa cosa se le tre pagine sopracitate ricevono link interni da altre pagine del sito (in questo caso puoi valutare un nofollow sui link interni dei “filtri”, ad esempio).
Insomma, fai in modo che ai crawler sia chiarissimo qual è la pagina che dovrebbe rispondere in modo inequivocabile a una determinata richiesta dell’utente.
Prevenzione delle cannibalizzazioni
Se non sai cosa intendo parlando di cannibalizzazione SEO, ti consiglio di leggere il post dedicato all’argomento. Lo trovi qui: https://andreabecchetti.com/imparare-seo/cannibalizzazione-seo/.
Come dicevo poco sopra, la duplicazione dei contenuti è pericolosa anche perché rende difficoltoso per il motore di ricerca scegliere quale contenuto debba essere mostrato agli utenti.
Quando due contenuti duplicati hanno una “forza simile”, c’è il grosso rischio che vadano in competizione l’un l’altro e, così facendo, si frenino a vicenda nella possibilità di posizionarsi in modo favorevole.
Se ti accorgi che hai un problema simile, canonicalizzare una pagina su un’altra può essere una soluzione blanda per risolvere la cannibalizzazione.
Risparmiare Crawl Budget
Il Crawl Budget è la quantità di tempo e risorse che i bot dei motori di ricerca utilizzano per scaricare i tuoi contenuti prima di indicizzarli.
Secondo te è meglio che il crawler impieghi risorse a scaricare migliaia di filtri o che si concentri nell’analisi delle pagine che tu vuoi vengano tenute in considerazione?
Questo è un ottimo motivo per canonicalizzare bene i contenuti. Per raccontarti velocemente un aneddoto, posso dirti che ho lavorato con un e-commerce di sport molto grande che aveva appena lanciato un restyling del suo sito.
E i filtri erano tutti aperti alla scansione e con un Canonical autoreferenziale.
Il risultato? Google continuava a chiamarli per l’analisi mandando in down il sito web. Questo è un caso limite ma, se capita a te o al sito del tuo cliente, è davvero importate sia qualcosa di insolito?
Facilitare le analisi
Pensa se trovi in SERP 5 pagine duplicate che producono risultato di clic e impression. Hai idea di che casino sia poi andare a pulire i report per avere chiarezza su cosa sta succedendo al tuo progetto?
Canonicalizzare, e quindi evitare che troppe pagine generino risultato per lo stesso contenuto (e quindi le stesse query), ti aiuta anche a tenere più pulito possibile la lettura dei risultati della tua strategia.
Come canonicalizzare le URL: rel Canonical e altre soluzioni
Ci sono svariati modi per fornire indicazioni ai motori di ricerca su quale sia il contenuto canonico. In questo articolo ti presenterò quelli che più spesso ho usato nello svolgere il mio lavoro, cercando di fornirti alcuni pro e contro su ciascuno di essi.
Rel Canonical
Il rel Canonical, chiamato anche tag Canonical o link Canonical è un’istruzione che puoi fornire ai motori di ricerca per segnalare quale, fra molti, è il contenuto canonico da prendere in considerazione.
Viene definita istruzione perché, come tale, può essere ignorata. Questo significa che il motore di ricerca può scegliere di non tenere in considerazione il Canonical che tu hai assegnato e considerare come principale una pagina differente da quella che vorresti.
É una cosa che succede più spesso di quanto non credi, soprattutto se hai involontariamente mandato in confusione il crawler fornendo indicazioni di deduplicazione contrastanti. Ad esempio, se hai scelto una pagina canonica ma in Sitemap hai lasciato anche il contenuto da ignorare. Oppure se, fra due pagine, hai scelto come canonica quella “meno forte”, che ha meno anzianità, meno link interni, meno backlink e via dicendo.
Se, però, stai attento a non fare confusione, nella mia esperienza posso dirti che i motori di ricerca rispettano la tua istruzione, perché partono dall’assunto che sei tu a sapere cos’è meglio mostrare agli utenti a proposito del tuo Brand.
Il link canonical si scrive come segue:
<link rel=“canonical” href=“https://www.sito.it/pagina-canonica.html”>
In questa porzione di codice trovi:
- l’attributo rel che fornisce l’istruzione su cosa me considerato il link;
- href che segnala invece qual è l’URL canonica.
Il tag Canonical si inserisce nell’head della pagina e segnala appunto che, data un URL A, il contenuto canonico (quindi quello da prendere in considerazione) è disponibile all’URL https://www.sito.it/pagina-canonica.htm.
Esiste anche un metodo alternativo per inserire il rel canonical ed è l’intestazione HTTP. L’indicazione del Canonical attraverso intestazione HTTP ha due differenze rispetto all’inserimento del link in head: non aumenta la dimensione della pagina (perché impostato lato Server e non inserito nel codice della pagina) e si estende anche a parti della pagina che non sono in Html (PDF o altri media, che sono al di fuori dell’Html).
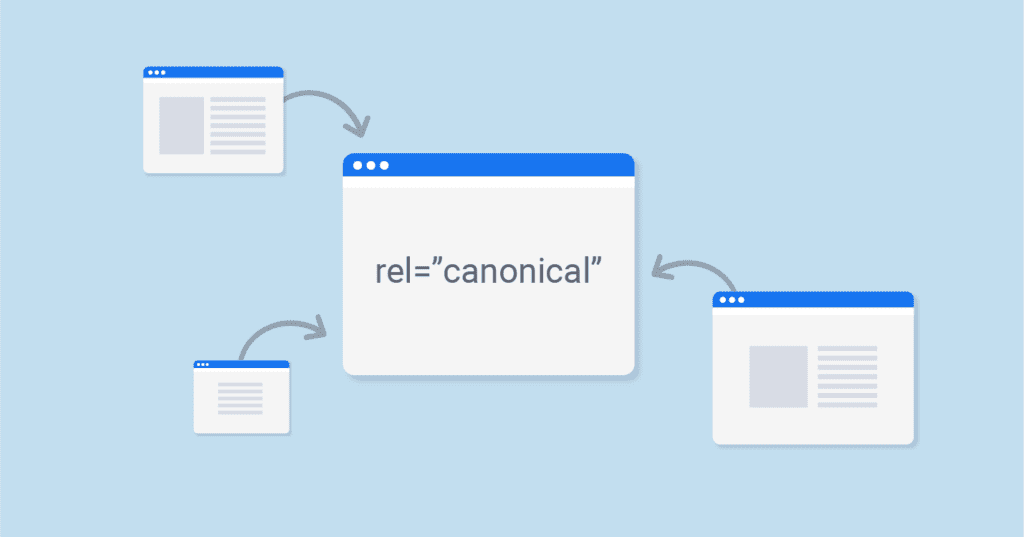
Come puoi vedere dall’esempio precedente, il rel Canonical centralizza l’importanza di un contenuto, sottomettendo gli altri.
La pagina in cui leggi <rel=“Canonical”> è appunto la pagina canonica, mentre le pagine ai lati sono quelle che comprenderebbero il link canonical che ti ho mostrato poco sopra.
Il rel Canonical è uno dei migliori alleati per quanto riguarda la canonicalizzazione dei contenuti, perché assolve praticamente a tutte le necessità di deduplicazione di Google e dei motori di ricerca: unifica i segnali di ranking dalle pagine duplicate, permette di risparmiare Crawl Budget e fornisce al motore di ricerca indicazioni inequivocabili su qual è il contenuto da mostrare agli utenti nei risultati di ricerca.
Quando usare il Rel canonical?
Personalmente, ho sempre considerato il Canonical la soluzione da prediligere quando devi avere online dei contenuti duplicati.
Un contenuto duplicato, in sé, non è uno dei quattro cavalieri dell’apocalisse. Lo diventa se non lo gestisci. La duplicazione è un fattore fisiologico in tutti i siti. Su quelli di grandi dimensioni (blog, ecommerce, magazine) è assolutamente inevitabile. Pensa anche soltanto all’ordinamento dei prodotti per prezzo ascendente o discendente. Nella maggior parte dei casi, l’URL che si crea è parametrata e quindi via coi duplicati.
Ma toglieresti mai quelle pagine dal sito? Ovviamente no.
In tutti questi casi il Canonical funziona di solito benissimo. Ti permette di tenere online tutte le pagine “di servizio” di cui hai bisogno senza rischiare che il crawler metta in SERP cose che non vorresti in SERP.
Come si inserisce il rel Canonical?
L’inserimento del link canonical all’interno di un contenuto è piuttosto semplice. Puoi inserirlo manualmente all’interno dell’head della pagina, utilizzando il codice che ti ho riportato poco più su.
Oppure, se hai un CMS, puoi sfruttare uno dei tanti plugin o moduli che facilitano l’ottimizzazione a livello di singola pagina. A seguire ti lascio uno screenshot della sezione URL canonico di SEOPress, il plugin che utilizzo su questo sito. Se usi Rankmath, Yoast SEO o qualsiasi altro plugin per WordPress, Prestashop, Magento o Joomla, troverai nelle impostazioni la stessa casella di inserimento.
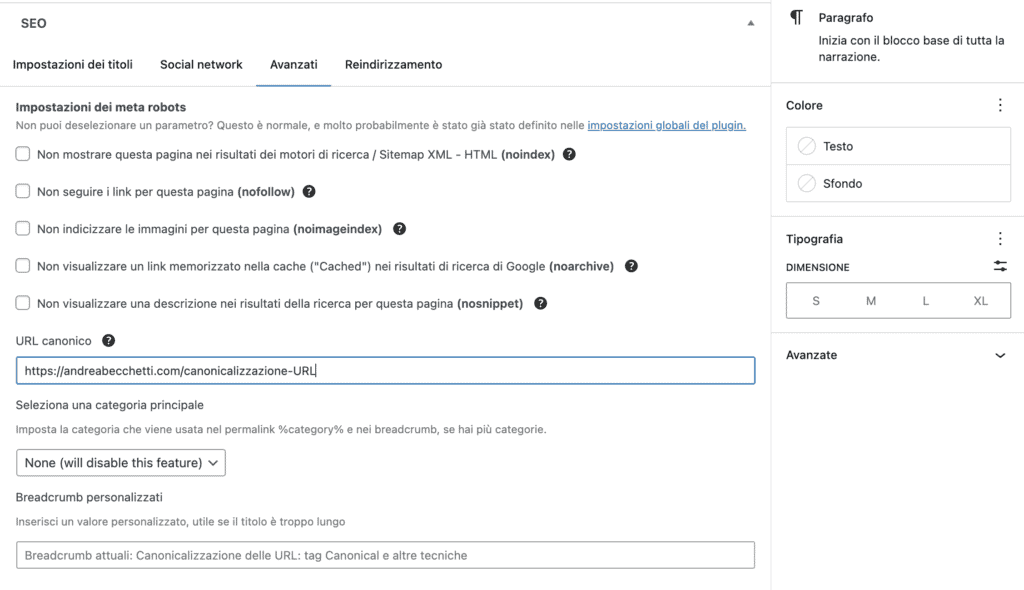
Ci tengo a sottolinearlo di nuovo: il rel canonical è un’indicazione. Se scegli di canonicalizzare una pagina A verso una pagina B, ma la pagina A è troppo forte (perché riceve tanti link, perché ha ottime metriche di gradimento degli utenti, perché è più “anziana”), Google potrebbe letteralmente fregarsene e continuare a valutare come canonica la pagina in cui hai inserito il link canonical.
Gestire la canonicalizzazone attraverso i redirect
Il reindirizzamento, o redirect, è un altro segnale molto forte di canonicalizzazione delle URL.
Avrai sicuramente già sentito parlare di redirect lato server 301. Quello che immagino tu utilizzi ogni qual volta elimini una pagina e segnali via server qual è la nuova pagina che ha preso il suo posto.
Impostare un redirect segnala al crawler che l’URL canonico da prendere in considerazione è l’URL target. Puoi farlo per tutte le URL che vuoi, a patto che il rendirizzamento abbia un senso.
Se hai tre pagine che parlano di tre cose differenti, che non hanno nessuna query in comune né contenuti simili, non fare un redirect. In quel caso, non c’è proprio niente da canonicalizzare!
Google ci segnala che sono validi tutti i metodi di reindirizzamento: dal classico 301 lato server al meta-refresh, passando per i reindirizzamenti in Javascript).
Per impostare un redirect esistono un sacco di modi. Puoi utilizzare il file htaccess piuttosto che compilare a mano le tabelle in uno dei millemila plugin SEO disponibili per i CMS più utilizzati.
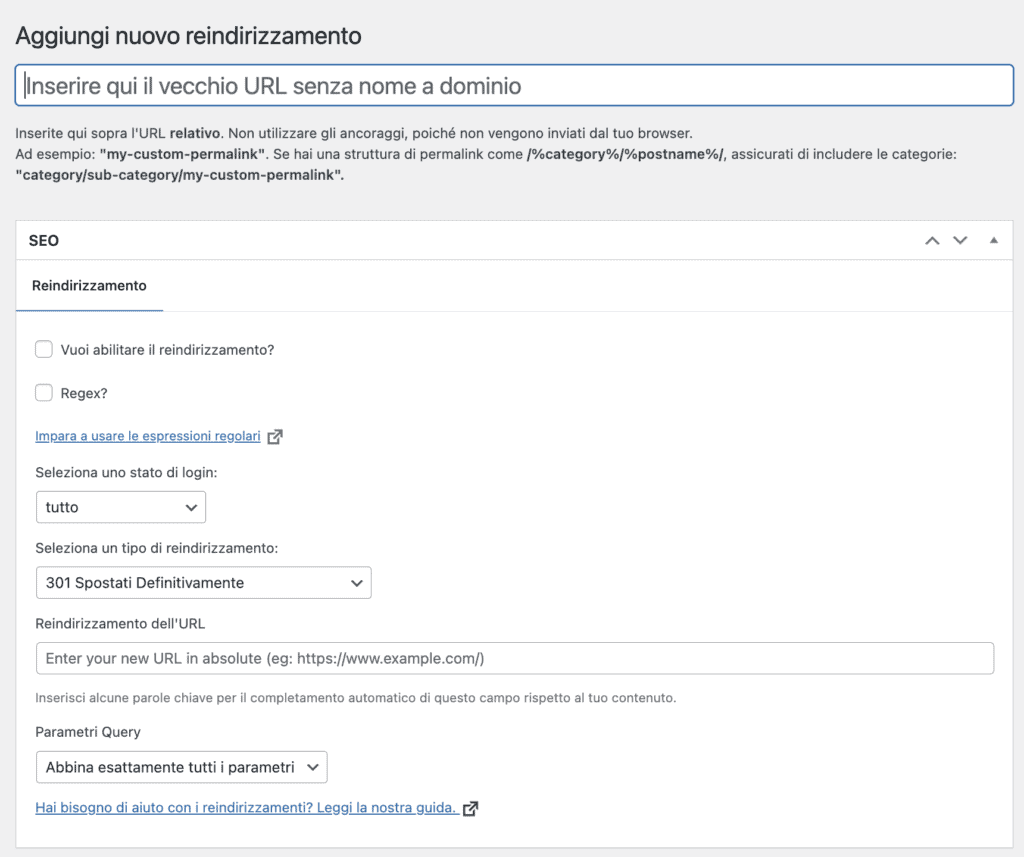
Il reindirizzamento è un ottimo modo per fornire indicazioni inequivocabili sulla canonicalizzazione dei contenuti. Ammesso che tu non abbia bisogno di avere online i contenuti duplicati per un motivo extra-seo.
Ad esempio, nel caso delle pagine dinamiche generate da filtri e ordinamento, l’utilizzo del canonical via redirect è ovviamente sconsigliabile.
Utilizzo della Sitemap per la canonicalizzazione
Dulcis in fundo, quell’elemento dei siti web che sovente viene quasi disprezzato o considerato come un surplus.
Le URL incluse nella Sitemap forniscono indicazioni ai motori di ricerca su qual è il contenuto canonico, quello che dovrebbe essere perso in considerazione per essere mostrato nella ricerca.
Probabilmente fra i metodi di canonicalizzazione è il più “debole”, ma può comunque generare dei casini. Soprattutto se inavvertitamente lasci nella Sitemap delle URL non canoniche (o perché hanno un canonical verso altre URL, o perché sono addirittura state reindirizzate).
Anche in questo caso, la Sitemap XML viene ormai quasi sempre gestita da tool e moduli esterni, che la generano sulla base delle istruzioni ricevute.

Quello che vedi sopra è una parte delle impostazioni di Sitemap XML di SEOPress. Anche in questo caso, esistono tonnellate di plugin e moduli che fanno questo lavoro. Ti serve soltanto sceglierne uno con cui testare.
Errori più comuni
Ok, prima di lasciarti andare ti do alcuni degli errori più comuni che ho fatto e visto fare nel corso degli anni.
- non fornire indicazioni contrastanti. Ad esempio, evita di avere URL che fanno canonical su contenuti differenti ma sono presenti in Sitemap;
- non usare il Canonical o i reindirizzamenti su contenuti che non c’entrano nulla l’uno con l’altro;
- attenzione ai link interni: se hai dei link che rimandano a delle pagine non canoniche, toglili o mettili in nofollow;
- assicurati che tutte le pagine Canoniche abbiano un rel Canonical autoreferenziale verso sé stesse;
- fai estrema attenzione alla gestione dei rendirizzamenti massivi, come quello da http a https e quello da non-www a www (o viceversa).
Conclusioni
Direi che anche per canonicalizzione, rel Canonical e compagnia ci siamo. Spero di averti fornito tutte le info di cui avevi bisogno per comprendere meglio questa tematica ma, se hai qualche dubbio, utilizza pure il form di domande qui sotto!
Sono un consulente SEO freelance e mi occupo di SEO e di marketing digitale. Questo è il mio sito personale, dove cerco di fare divulgazione e formazione a professionisti e imprenditori sull’ottimizzazione per i motori di ricerca e il digital marketing. Se hai necessità di aiuto con il tuo progetto, guarda la mia pagina di servizi SEO.




